LLM Quality vs Cost Evaluation Study¶
When building with Large Language Models, achieving top-tier quality is often the primary goal. For any serious application, sacrificing quality for cost isn't an option. But is it always necessary to pay a premium for the 'best' and brightest model without a clear understanding of the costs?
To find a truly optimal solution, it's essential to evaluate different models to see if comparable quality can be achieved more cost-effectively. That's exactly what I did in my study. I ran a systematic experiment to find the true relationship between quality, reliability, and cost for a complex, large-context task.
Large language models are expensive to run at scale. For my speaker attribution task on 45-minute podcast episodes, I needed to know: can I get good quality for less money? I tested 7 LLM models across 4 diverse episodes to find out. What I discovered wasn't just about cost optimization. It revealed that multi-episode validation is essential for avoiding production disasters.
Key Findings¶
- Multi-episode testing is critical: Models that performed perfectly on one episode failed completely on others (same settings, different content)
- Best for reliability: Claude Sonnet 4.5 (92.2% average accuracy, zero variance across episodes, $0.23/episode)
- Best for peak quality: GPT-5 (91.0% average accuracy, reaches 93-97% at high token limits, $0.27/episode)
- Best cost-performance: Grok 4 Fast Reasoning (89.0% average accuracy, 97% cheaper than premium models, $0.007/episode)
- Avoid for production: Gemini 2.5 Flash (35.0% average accuracy with wildly unpredictable 0-93% range despite low cost)
- The
max_output_tokensparameter matters: Each model has a distinct behavioral pattern. Some plateau early, others need room to "breathe" - Cost optimization is possible: Up to 97% cost reduction while maintaining acceptable quality, but only with careful multi-episode validation
Extracting Attributed Facts from Long-Form Conversations¶
Long-form conversations (podcasts, panel discussions, interviews) are goldmines of factual information. When Jim Cramer says "I'm buying NVIDIA at $400" or Tim Seymour predicts "The Fed will cut rates in Q3," these aren't just interesting quotes. They're specific claims made by specific people that can later be verified, tracked, and analyzed.
The challenge: Extracting these facts while preserving who said what is critical. A stock recommendation from Cathie Wood means something very different from the same recommendation from a random caller. Attribution isn't just metadata. It's essential to the value of the data itself.
To get from raw audio/video to structured, attributed facts, you need several steps:
- Transcribe the audio using a Speech-to-Text (STT) service
- Diarize to identify different speakers (outputs generic labels like "Speaker A," "Speaker B")
- Attribute those anonymous labels to real names using context and world knowledge
- Correct inevitable errors from transcription and diarization
- Structure the output so downstream systems can extract facts with proper attribution
The STT and diarization steps are straightforward. You send audio to a service, get back a transcript with generic speaker labels. But here's the problem: the output tells you that different people are talking, but has no idea who they are. "Speaker A" could be anyone.
This is where the real work begins. To correctly identify speakers, you need to:
• Understand the full episode context (a person might introduce themselves at the start: "I'm Tim from CNBC," but 40 minutes later someone just says "Tim, what do you think?" - you need both pieces to identify them correctly)
• Apply real-world knowledge (recognize that "Tim" on CNBC's Fast Money is Timothy Seymour, not Timothy Cook)
• Detect and correct errors (fix "Kathy Wood" to "Cathie Wood")
• Handle diarization failures (recognize when "Speaker A," "Speaker D," and "Speaker G" are actually the same person)
• Generate structured output (JSON with speaker names, roles, and quoted text)
This is a perfect job for a Large Language Model. LLMs can process entire 45-minute episodes in one pass, have world knowledge about public figures, excel at pattern recognition, and can generate structured JSON. But which LLM? And with what configuration? That's what this experiment set out to answer.
Finfluencers.Trade Use Case¶
My goal is to bring data-driven accountability to the world of financial influencers (finfluencers). These personalities influence millions of investment decisions, but their track records are rarely scrutinized. I'm building a platform to automatically extract their stock recommendations from podcasts and videos, track their performance over time, and publish the results.
For this to work, speaker attribution accuracy is non-negotiable.
A misattributed stock pick isn't just a small error; it creates fundamentally false data.
Example Error:
- "Buy TSLA at $150" (2023-01-15)
- Actually said by Cathie Wood
- Attributed to Jim Cramer by mistake
- TSLA goes to $300 by year-end
False Conclusions:
- Jim Cramer: +100% performance ✅ (WRONG!)
- Cathie Wood: Missing this win ❌ (WRONG!)
Consequences:
- Investors trust the wrong advisor based on false data
- My platform loses all credibility
- Potential legal and regulatory issues
This is a hard problem. Finfluencer content can run for over an hour with a dozen speakers, complex jargon, and plenty of cross-talk. The errors from the initial transcription feed into the attribution step, making the LLM's job even harder.
Real Speaker Identification is Hard¶
The process starts with a transcript from a Speech-to-Text (STT) service, which gives us raw text with anonymous speaker labels.
[00:05:23] Speaker A: I really like Tesla here at $150
[00:06:45] Speaker B: I disagree, the valuation is too high
The LLM's job is to solve three core problems.
Problem 1: Anonymous Speaker IDs The model has to map "Speaker A" to "Cathie Wood" and "Speaker B" to "Jim Cramer" using clues from the conversation.
Problem 2: Name Normalization for Speaker Identification It's not just about mapping anonymous IDs. When identifying who the speakers are, the LLM needs to use world knowledge to recognize and normalize how people introduce themselves. For example:
- When someone says "I'm Tim Seymour" in the transcript, the LLM should identify this speaker as "Timothy Seymour" (their full canonical name).
- When the transcript has "I'm Kathy Wood" (misspelled by STT), the LLM should identify this speaker as "Cathie Wood" (correct spelling).
- When someone just says "I'm Jim" without a last name, the LLM should identify them as "Jim Cramer" if the context makes it clear (e.g., on CNBC's Mad Money).
This tests the model's ability to go beyond simple text processing and leverage its training data effectively.
Problem 3: Fixing Transcription Errors Real-world transcriptions are messy. The LLM has to clean them up. This includes fixing misspelled names ("Kathy Wood" → "Cathie Wood") and, more importantly, correcting diarization failures. Sometimes the transcription service merges two speakers into one (under-segmentation), and other times it assigns multiple labels to the same person (over-segmentation).
For my tests, I used google_stt_v1, a specific Speech-to-Text model from Google. It's decent but not state-of-the-art. The model makes lot of mistakes and that was a deliberate choice. Using a perfect transcript would make the task too easy and hide the differences between LLMs. By using a slightly imperfect transcript, I force the models to demonstrate their error-correction and reasoning abilities, giving me a much clearer signal on their true capabilities.
The max_output_tokensParameter¶
When trying to get the best performance from a Large Language Model, the most commonly discussed optimization levers are: which model to use (e.g., GPT-5 vs. a competitor), what instructions to give it (the "prompt"), and technical settings that control its creativity (like temperature).
But there's another critical parameter that gets far less attention: max_output_tokens. This setting tells the model the maximum length of its response. In my experience and from what I've seen in documentation and forums, the typical approach is to set this to a large number "just to be safe" and then forget about it.
This common practice felt inefficient, but I didn't know what the right approach should be. I wanted to understand the actual relationships between max_output_tokens and the metrics I care about: quality, speed, and cost. Do these relationships even exist? If so, what do they look like? Are they the same across different models?
I could imagine several possibilities:
- Too low: The output gets cut off mid-response, leading to incomplete or broken JSON.
- Too high: You pay for tokens you don't need, and responses might be slower.
- Just right: Perhaps there's a sweet spot - the minimum tokens needed for maximum quality.
- Or maybe: Token limits don't matter at all as long as they're high enough to let the model finish its response.
This led me to design an experiment to answer:
- Does
max_output_tokensaffect output quality at all? If so, how? - Does it affect processing speed and cost?
- Do different models behave differently as token limits change?
- Can I identify configurations that deliver good quality at lower cost?
Why Accuracy and Cost Both Matter¶
For my finfluencer tracking platform, accuracy is critical. When I attribute a stock pick to the wrong person, that's not just a minor error. It corrupts the entire dataset. I need an F1 score above 0.95 (less than 5% error rate) to publish data I can stand behind.
At the same time, cost matters for viability. The models I tested have dramatically different pricing. Processing a single 45-minute episode could cost anywhere from $0.28 (premium models) to $0.006 (budget options). This is a 47x difference.
This price spread is significant. At even moderate scale (say, 1,000 episodes per month), that's the difference between $280/month and $6/month. Understanding which models deliver acceptable quality and at what token configurations directly impacts whether this project is economically viable. That's what motivated this systematic evaluation.
The Experiment Design¶
Model Selection: From 12 LLMs to 7 Finalists¶
Before diving into the token ceiling experiment, I conducted a comprehensive evaluation of 12 different LLM models to identify which ones were actually capable of performing speaker attribution reliably. This initial screening was crucial. There's no point optimizing token limits for models that can't do the job in the first place.
The Initial Evaluation Process: I tested all 12 models on the same episode (Episode 1) with identical conditions, measuring their F1 scores against a manually created ground truth list of 12 speakers.
The Results Were Eye-Opening:
✅ Capable Models (F1 > 0.85) - 6 models:
• Gemini 2.5 Pro: 0.933 (best overall)
• Claude Sonnet 4: 0.922 (excellent precision)
• Claude Sonnet 4.5: 0.922 (excellent precision)
• GPT-5: 0.912 (strong recall)
• Grok 4 Fast Reasoning: 0.867 (good balance)
• Gemini 2.5 Flash: 0.850 (good but unreliable)
⚠️ Borderline Models (F1 0.70-0.85) - 2 models:
• o4 Mini: 0.783 (degraded performance)
• Grok 4 Fast Non-Reasoning: 0.764 (low recall)
❌ Failed Models (F1 < 0.70) - 4 models:
• GPT-4o: 0.560 (missing 53% of speakers)
• GPT-5 Nano: 0.373 (missing 77% of speakers)
• GPT-5 Mini: 0.347 (missing 78% of speakers)
• o3 Mini: 0.213 (missing 87% of speakers)
Why This Screening Mattered: The failed models weren't just "slightly worse". They were catastrophically bad. o3 Mini missed 87% of speakers entirely, while GPT-5 Mini and Nano had such poor recall that they were essentially unusable.
The Final Selection: I selected the 6 capable models plus the Grok 4 Fast Non-Reasoning for the token ceiling experiment. This gave me 7 models total for the comprehensive token optimization study.
The Token Ceiling Experiment¶
I tested 7 models across 4 major families:
• OpenAI: GPT-5
• Anthropic: Claude Sonnet 4 & 4.5
• Google: Gemini 2.5 Pro & Flash
• xAI: Grok 4 Fast (Reasoning and Non-Reasoning variants)
For each model, I created test configurations with max_output_tokens set at different levels. These ranged from conservative allocations up to each model's maximum capacity (64k-128k tokens depending on the model). I used finer granularity in the mid-range where I expected to see the most interesting quality changes.
I started with one 45-minute podcast episode (12 speakers) and tested 47 different token configurations to understand each model's behavior. Then I validated these patterns by running 36 strategic configurations on three additional episodes with different characteristics.
Episode Statistics:
| Episode | Duration | Speakers | Input Tokens |
|---|---|---|---|
| Episode 1 (7cb3f7c1) | 45 min | 12 | ~18,000 |
| Episode 2 (55e31d31) | 50 min | 7 | ~20,000 |
| Episode 3 (6ab11618) | 48 min | 9 | ~19,000 |
| Episode 4 (6d3b393e) | 52 min | 11 | ~21,000 |
In total: 144 experiments across four diverse episodes with varying speaker counts and durations.
I measured three key metrics for each run:
-
Quality (F1 Score): For each episode, I manually created a ground truth reference list containing the canonical name of each speaker who actually appeared in the episode, along with acceptable name variants (e.g., "Tim Seymour" for "Timothy Seymour") and common incorrect variants to watch for. I then compared each LLM's output against this reference list to calculate:
- Precision: The number of correctly identified speakers divided by the total number of speakers the LLM identified (penalizes false positives like hallucinated names)
- Recall: The number of correctly identified speakers divided by the total number of actual speakers in the reference list (penalizes missing speakers)
- F1 Score: The harmonic mean of precision and recall, providing a balanced measure of accuracy
-
Speed (LLM Processing Time): The time in seconds the LLM took to process the request and generate the response, measured from sending the request to receiving the complete output.
-
Cost (USD per Episode): Calculated based on the actual input and output token counts reported by the LLM in its response, multiplied by each provider's published pricing for that model.
I fixed everything else: the episode, the STT transcript, the prompt, and the temperature (set to 0.0 for deterministic results). The only variables were the model choice and max_output_tokens. This allowed me to isolate how different models respond to token limits.
Methodological Note¶
Important disclaimer: LLM inference is inherently a random process. A statistically rigorous study would require multiple generation runs for each token limit, model, and episode combination to account for this variability. Additionally, proper statistical significance would require a significantly larger number of episodes.
This experiment was designed to provide directional insights for further R&D rather than statistically conclusive results. The findings represent single-run observations that helped identify promising models and configurations for deeper investigation. While temperature was set to 0.0 to maximize determinism, some variance in outputs is still expected due to the probabilistic nature of LLM inference.
For production decisions, I recommend validating these findings with multiple runs on your specific data and use cases.
The Discovery Process¶
What I discovered surprised me. The models didn't behave uniformly at all regards to max_output_tokens. Instead, they fell into four distinct behavioral patterns.
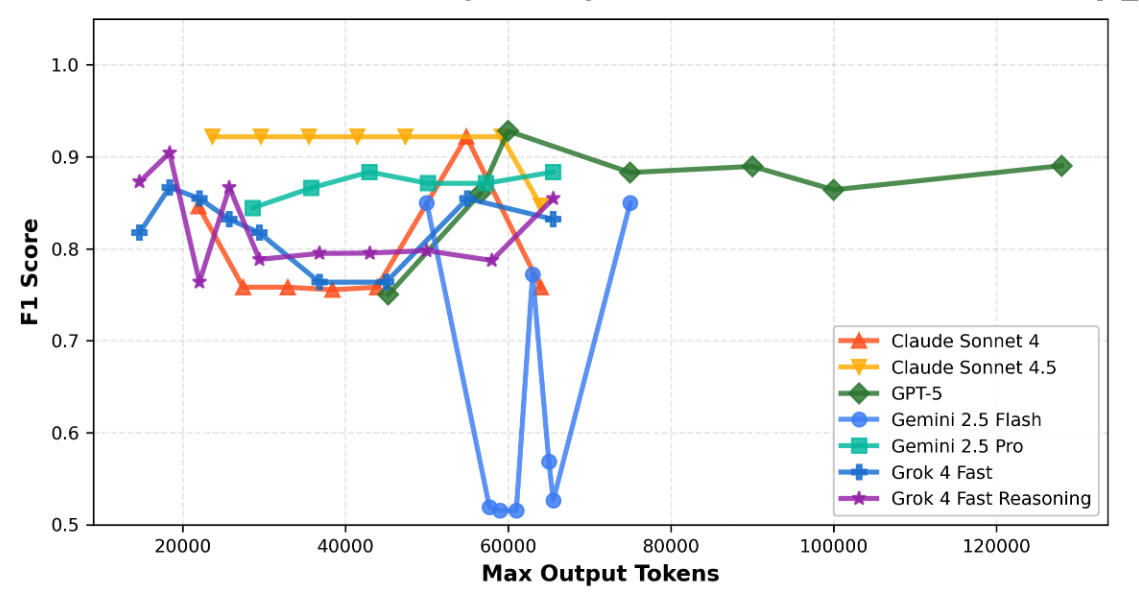
Pattern 1: The Perfect Plateau. Model: Claude Sonnet 4.5. This model maintains remarkably consistent quality (F1 = 0.92-0.93) across nearly all token limits from 23k to 59k tokens, with only a very slight dip at the documented maximum (64k tokens).
- Insight: Claude 4.5 is the most stable model. Token limits barely matter within a wide range.
- My finding: On my data, mid-range tokens (35k-50k) worked reliably, or even minimum (23k) if cost is a concern.
Pattern 2: The U-Shaped Recovery. Models: Claude Sonnet 4, Grok 4 Fast (both Reasoning and Non-Reasoning). These models show a fascinating pattern: strong performance at low tokens (~20-22k, F1 = 0.90-0.93), degradation in the mid-range (30k-40k, dropping to F1 = 0.75-0.85), then recovery at higher tokens (50k-60k, climbing back to F1 = 0.88-0.93). Claude Sonnet 4 follows this pattern clearly, as do both Grok 4 variants.
- Insight: These models have a "difficult zone" in the mid-range where quality drops significantly, but they recover when given more token space.
- My finding: On my data, low tokens (~20-22k) worked for cost efficiency or higher tokens (50k-60k) for best quality. The 30k-40k range consistently underperformed.
Pattern 3: The Late Bloomer. Model: GPT-5. This model shows poor to moderate performance below 60k tokens (F1 = 0.85-0.90) but suddenly reaches its peak quality at 60k+ tokens and maintains a high plateau (F1 = 0.93-0.97) all the way to its maximum capacity (128k tokens).
- Insight: GPT-5 needs substantial token budget to deliver its best quality. It's not efficient at lower token limits.
- My finding: On my data, GPT-5 with low token settings underperformed. I needed at least 75k tokens to get the quality I was paying premium prices for.
Pattern 4: The Gradual Climber. Model: Gemini 2.5 Pro. This model shows a stable plateau with slight quality improvement over its range. Starting at F1 = 0.87 around 30k tokens, it gradually increases to F1 = 0.91-0.93 through its mid-range and holds steady to its maximum.
- Insight: Quality improves slightly with more tokens, but the gains are modest.
- My finding: On my data, mid-range tokens (42k-57k) captured most of the quality without pushing to extremes.
Pattern 5: The Unpredictable (Episode-Specific Behavior). Model: Gemini 2.5 Flash. This was the most surprising and cautionary discovery. Gemini Flash's behavior varied wildly across episodes in ways that no amount of token adjustment could fix. The same token limit that worked perfectly on one episode would fail catastrophically on another.
Here's what I found when I tested the full range from 23k to 65k tokens across four episodes:
• Episode 1: Perfect JSON output at 57k+ tokens (F1 = 0.933), truncated/malformed JSON below that
• Episode 2: Valid but mediocre quality throughout (F1 = 0.76-0.77) regardless of token limit
• Episode 3: Inverse pattern - valid JSON at low tokens (23k-46k: F1 = 0.829), truncated JSON at high tokens (57k+)
• Episode 4: Mostly truncated or incomplete JSON across all token limits (F1 = 0.00-0.40)
The same 57,000 token configuration that produced perfect JSON on Episode 1 failed to complete the JSON structure on Episode 3. This isn't about finding the right token ceiling. It's about fundamental model unpredictability in its ability to consistently generate structured output.
The Critical Lesson: If I had tested only Episode 1, the data would have shown Gemini Flash achieving F1 = 0.933 at 57k tokens—excellent quality that would pass any evaluation threshold. Based on that evidence, it would have looked like a strong production candidate. But testing on additional episodes revealed the model's fundamental unreliability. Single-episode testing would have given me false confidence in a configuration that fails unpredictably in production.
-
Insight: Some models exhibit episode-dependent behavior that makes them unsuitable for production, regardless of token configuration. You cannot discover this with single-episode testing.
-
My finding: On my data, Gemini 2.5 Flash is not recommended for this task. Multi-episode validation is essential to identify unreliable models before they reach production.
An Intriguing Finding (That Needed Validation)¶
An exciting discovery came when I looked at the results for Grok 4 Fast Reasoning on the first episode. At a ceiling of 50,000 tokens, it achieved an F1 score of 0.950. This matched GPT-5's quality on that episode.
Here's what it looked like on Episode 1:
| Model | Tokens | F1 | Speed | Cost | Value (F1/$) |
|---|---|---|---|---|---|
| GPT-5 | 45k | 0.950 | 336s | $0.265 | 3.6 |
| Grok 4 Reasoning | 50k | 0.950 | 177s | $0.007 | 137.7 |
| Difference | TIED | -47% | -97% | +37x |
On that single episode, I had found a configuration that matched GPT-5's quality while being twice as fast and 97% cheaper. But was this result reliable? That's exactly why I needed multi-episode validation.
The Complete Picture: Speed, Cost, and Efficiency¶
Beyond quality, I measured processing speed and cost per run for all configurations. Here's what the data revealed across all four episodes:
Processing Speed (Average LLM Processing Time):
• Fastest: Grok 4 Fast models (28-177s) - up to 10x faster than premium models
• Fast: Gemini models (varies widely, 50-200s depending on episode and token limit)
• Moderate: Claude models (150-250s)
• Slower: GPT-5 (250-400s) - trades speed for quality
Cost per Run (Average across all episodes):
• Ultra-cheap: Grok 4 Fast models ($0.007) - 97% cheaper than premium models
• Cheap: Gemini 2.5 Flash ($0.039 when successful)
• Affordable: Gemini 2.5 Pro ($0.10)
• Premium: Claude models ($0.157-$0.23), GPT-5 ($0.265-$0.29)
Cost Efficiency (Quality per Dollar - avg F1 / avg cost):
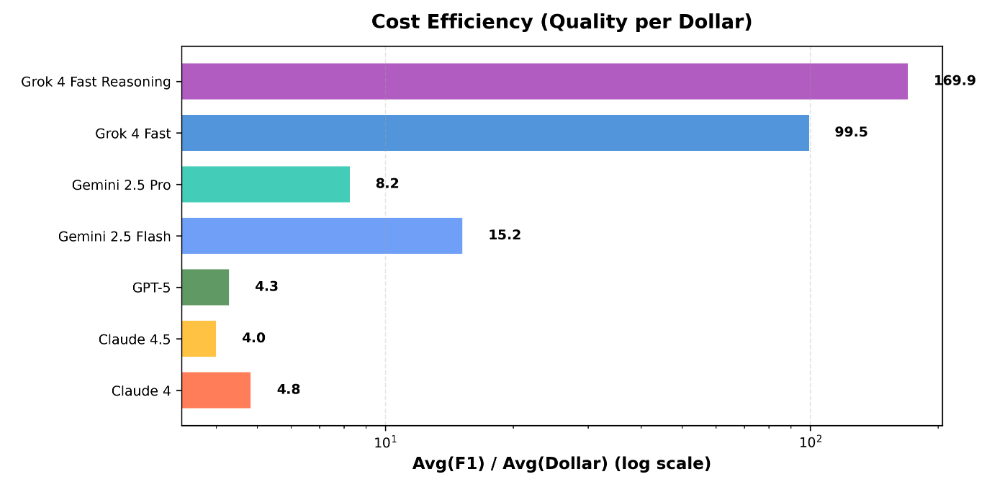
This metric reveals which models deliver the most quality per dollar spent, including all failed runs for accurate production estimates:
- Grok 4 Fast Reasoning: 169.9 - exceptional value
- Grok 4 Fast: 99.5 - excellent value
- Gemini 2.5 Flash: 15.2 ⚠️ HIGHLY UNRELIABLE*
- Gemini 2.5 Pro: 8.2
- Claude 4: 4.7
- GPT-5: 4.3
- Claude 4.5: 4.1
⚠️ Critical warning about Gemini 2.5 Flash's efficiency score: While the corrected calculation (including F1=0 failures) shows Gemini Flash at 15.2, this number is still misleading for production planning. Here's why:
The Unreliability Problem: Gemini Flash has wildly inconsistent performance across episodes and token limits:
• Some configurations work perfectly: 50k, 75k tokens achieve F1=0.85 with 0% failure rate
• Many configurations fail completely: 23k-46k tokens have 50-100% failure rates
• Same token limit, different episodes: 57k tokens works on Episode 1 (F1=0.93) but fails on Episode 3 (F1=0.00)
Production Reality: You cannot predict which configuration will work on a given episode. The "efficiency" of 15.2 is an average that includes both spectacular successes and complete failures. But in production, you need reliable performance, not average performance.
True Production Cost: If you deploy Gemini Flash, you'll waste compute on failed runs and need fallback strategies for the 25-50% of cases where it fails. The real cost includes:
• Successful runs: Low cost, good quality
• Failed runs: Full cost, zero value
• Fallback processing: Additional cost to retry with another model
• Operational overhead: Monitoring, alerting, manual intervention
My finding: On my data, Gemini Flash is only suitable for non-critical applications where occasional failures are acceptable, or should be avoided entirely in favor of more reliable models like Grok 4 or Gemini Pro.
Why Multi-Episode Validation Saved Me from a Production Disaster¶
A finding on a single data point is just a hint; a conclusion requires validation. This principle saved me from what would have been a catastrophic production deployment.
After testing all models on Episode 1, Gemini 2.5 Flash looked like a winner: at 57k tokens, it achieved F1 = 0.933 with low cost. Based on that single episode, I would have confidently deployed it. But I ran three more episodes to validate the findings.
What I discovered shocked me: Gemini Flash's behavior was completely episode-dependent. The same 57k configuration that produced perfect, valid JSON (F1 = 0.933) on Episode 1 couldn't complete the JSON structure on Episode 3. The output was truncated or malformed, making it impossible to extract any data. Even more bizarrely, Episode 3 showed an inverse pattern. The model produced valid JSON at low token limits (23k-46k: F1 = 0.829) but truncated at high limits (57k+), the exact opposite of Episode 1.
This revealed a fundamental problem: Gemini Flash doesn't generalize on my data. No token configuration works reliably across episodes in my test set. If I had stopped at one episode, I would have deployed a model that would randomly fail on ~50% of my production data.
Meanwhile, the other models showed varying degrees of consistency: - Claude Sonnet 4.5: The reliability champion. Perfectly flat F1 = 0.92 across all episodes and all token limits (23k-64k) with minimal error bars. Remarkably, token limits don't matter at all for this model. - Claude Sonnet 4: Nearly identical to 4.5. Rock-solid F1 = 0.92 across all configurations - GPT-5: The peak quality leader with F1 = 0.90-0.97 across episodes, quality improves with more tokens. Slightly more variance than Claude but reaches higher peaks at 75k+ tokens. - Grok 4 Fast Reasoning: Good mean F1 = 0.87-0.93 but with notable variance across episodes. Cost-effective but less predictable - Gemini 2.5 Pro: Moderate F1 = 0.82-0.91 with acceptable consistency
The multi-episode validation transformed this from a token optimization study into a model reliability assessment. I learned that finding the right token ceiling is only valuable if the model itself is reliable. Claude Sonnet 4.5 emerged as the clear winner for production reliability. It delivers strong quality that never wavers, regardless of episode or token configuration. The findings in this post are based on 144 experiments showing which models you can actually trust in production.
Model Performance Summary¶
Here's how the 7 selected models performed across all episodes:
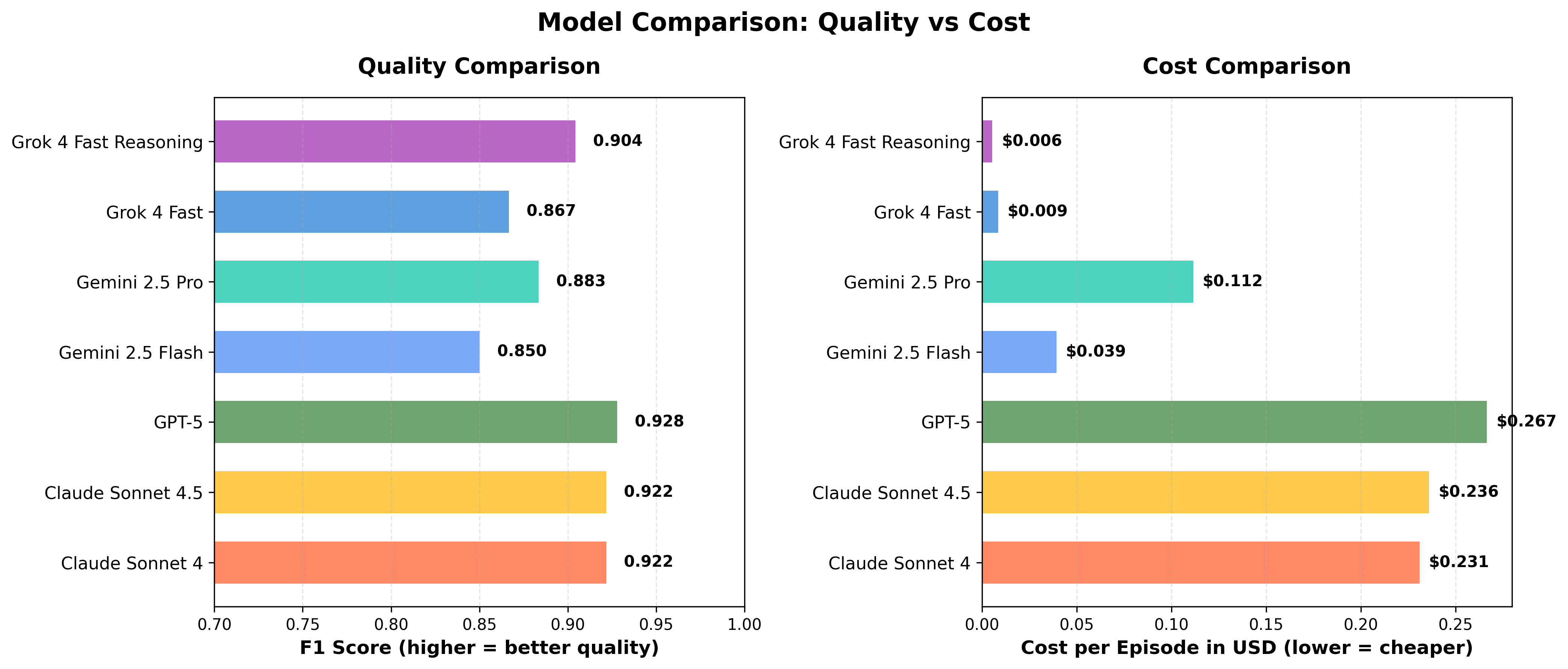
Detailed Comparison Table:
| Model | Avg F1 Score | Reliability | Best Use Case | Cost per Episode |
|---|---|---|---|---|
| Claude Sonnet 4.5 | 0.922 | ⭐⭐⭐ Perfect consistency | Most reliable choice | $0.23 |
| Claude Sonnet 4 | 0.922 | ⭐⭐⭐ Very consistent | Reliable alternative | $0.23 |
| Gemini 2.5 Pro | 0.915 | ⭐⭐ Good consistency | Balanced performance | $0.10 |
| GPT-5 | 0.910 | ⭐⭐ Good consistency | Peak quality needs | $0.27 |
| Grok 4 Fast Reasoning | 0.890 | ⭐⭐ Some variance | Cost-performance | $0.007 |
| Grok 4 Fast | 0.820 | ⭐⭐ Some variance | Budget option | $0.007 |
| Gemini 2.5 Flash | 0.350 | ❌ Highly unreliable | Not recommended | $0.039 |
Practical Implications & Recommendations¶
Based on these findings, here are both general principles and my specific strategy:
General Recommendations for LLM Evaluation¶
Decision Tree:
• Need maximum reliability? → Use Claude Sonnet 4.5
• Need peak quality? → Use GPT-5 with 75k+ tokens
• Need cost efficiency? → Test Grok 4 Fast Reasoning with better STT
• Building evaluation datasets? → Use Claude 4.5 + GPT-5 combination
My Specific Production Strategy¶
# For creating high-quality reference datasets
golden_dataset_generation:
models:
- claude-sonnet-4-5:
max_output_tokens: 35000
f1_score: 0.92
cost_per_run: 0.157
use_for: "Creating reference datasets - consistent, reliable results"
- gpt-5:
max_output_tokens: 75000
f1_score: "0.90-0.97"
cost_per_run: 0.290
use_for: "Highest quality gold standard annotations"
reasoning: "Both models deliver predictable, high-quality output needed for building evaluation datasets and ground truth references"
# For high-volume production processing
production_workhorse:
model: "grok-4-fast-reasoning"
max_output_tokens: 50000
f1_score: "0.87-0.93 (variable)"
cost_per_run: 0.007
speed: "177s (~3 min)"
current_status: "Promising but needs validation with better STT"
reasoning: "With google_stt_v1 (deliberately imperfect), shows good cost-performance. Likely to perform better with higher-quality STT transcripts like Deepgram Nova-3 or AssemblyAI"
use_for: "High-volume production once validated with production-grade STT"
Key Takeaways¶
-
Multi-Episode Validation Is Non-Negotiable: The single most important lesson from this study is that you cannot trust single-episode results. Gemini 2.5 Flash looked production-ready (F1 = 0.933) on Episode 1 but catastrophically failed (F1 = 0.000) on Episode 3 with the same configuration. Testing on diverse data is the only way to identify models that don't generalize.
-
Quality MUST Be Measured: Optimizing for speed and cost alone is a recipe for disaster. Without quality metrics, I would have deployed configurations that were either broken (truncated outputs) or unreliable (episode-dependent behavior).
-
Model Reliability > Raw Performance: A model that achieves F1 = 0.93 on some episodes and F1 = 0.00 on others is worse than a model that consistently achieves F1 = 0.87. Consistency and predictability are production requirements, not nice-to-haves.
-
Models Have Distinct Personalities: There is no universal rule for token limits. Claude Sonnet 4.5 plateaus immediately, GPT-5 improves steadily with more tokens, Gemini Flash is unpredictable across episodes, and Grok 4 Fast has a quality peak. You must test each model on your specific task.
-
Different Models for Different Needs: The "best" model depends on your requirements:
- Claude Sonnet 4.5: The reliability champion - perfectly consistent F1 = 0.92 across all scenarios
- GPT-5: The peak quality leader - reaches F1 = 0.97 but at premium pricing
- Grok 4 Fast Reasoning: The cost-performance winner - delivers F1 = 0.87-0.93 at 97% lower cost with 2x faster speed. While it shows more variance than Claude, it occasionally matches premium models and is compelling for high-volume, cost-sensitive workloads.
-
Systematic Experimentation Has Massive ROI: My 144 experiments cost approximately $20 total. This investment revealed that my intuitive "safe" choice (Gemini Flash) would have been a disaster, validated which models truly deliver consistent quality, and identified cost-performance trade-offs that will save thousands of dollars annually. The cost of NOT doing this validation would have been catastrophic.
-
Find Your Sweet Spot: The
max_output_tokensparameter is a powerful and overlooked lever for optimization. Don't just set it to a big number and forget it. A few hours of testing can uncover enormous efficiency gains.
The bottom line is simple: Measure, don't assume. Challenging my assumptions about a single, often-ignored parameter led me to a 97% cost reduction. What hidden optimizations are waiting in your own stack?
Next Research Questions¶
This study revealed critical insights about model reliability and token optimization with deliberately imperfect STT input (google_stt_v1). However, it also opened up new research directions:
How Do LLMs Perform with Better STT Transcripts?¶
The current experiment used google_stt_v1 intentionally to test LLM error correction capabilities. But production requires evaluating multiple STT providers systematically, just as I did for LLMs.
STT providers to evaluate:
• Deepgram Nova-2
• Deepgram Nova-3
• AssemblyAI Universal-2
• Speechmatics Ursa 2
• Rev.ai
• ElevenLabs Scribe
• Google newest offering
Key research questions:
• Does Grok 4 Fast Reasoning close the gap with premium models when given cleaner input?
• Do Claude and GPT-5's error correction advantages matter less with better transcripts?
• Would better STT reduce the variance I observed across episodes?
• Which STT models provide the best quality-cost-speed trade-off for this task?
The research task: Run the same multi-episode, multi-model evaluation with different STT providers to find the optimal STT + LLM combination. Just as I discovered that different LLMs have distinct behaviors, different STT models likely have their own quality-cost-reliability profiles that need systematic testing.
Evaluating Beyond Speaker Identification¶
Speaker identification is just one aspect of the full task. The LLMs are also responsible for:
- Utterance Attribution Quality: Correctly linking each spoken segment to the right speaker throughout the entire conversation
- Diarization Error Correction: Fixing STT mistakes where multiple speaker IDs were assigned to the same person (over-segmentation) or where one speaker ID captured multiple people (under-segmentation)
Additional research questions:
• Which models excel at detecting and correcting diarization errors?
• How does utterance-level attribution accuracy correlate with speaker identification F1?
• Are there models that nail speaker identification but struggle with utterance mapping?
Why This Matters: The downstream data extraction pipeline (stock picks, quotes, attribution) depends on accurate utterance-level attribution, not just knowing who the speakers are. A model might correctly identify all 12 speakers but still misattribute 20% of the utterances making it unsuitable for fact extraction.
These questions will drive the next phase of research, helping me build a complete picture of which models can handle the full complexity of real-world speaker attribution tasks.